Проектные решения
Проектные решения
Подключение библиотек настроек организационно-технологической структуры
В соответствии с соглашениями о моделировании в модели используется парадигма (система понятий) – роль. Именно роль выполняет бизнес-функцию, является ее хозяином. Именно роль является элементом окружения практически любой функции (рис. 23).

Рис. 23
Для связывания ролей с должностями и конкретными исполнителями применяется механизм создания организационной модели. Создается модель типа Organization Charts. Элементами ее становятся объекты типа Person Type (роли). Далее создается еще одна модель типа Organization Charts, на ней располагаются иерархически организованные объекты типа Organization Unit (подразделение) и Position (должность) (рис. 24).
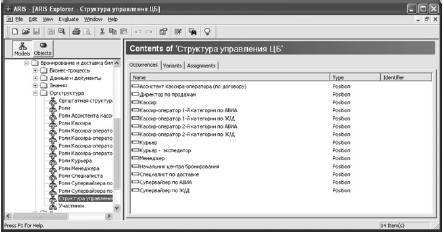
Рис. 24
И наконец, последний этап – формируется модель типа Organization Charts, на которой располагаются объект Position (должность) и связанный с ним набор объектов типа Person Type (роль). Мы получаем модель, определяющую зависимость подразделение – его должностной состав, а для каждой должности – ее исполнителя и список обязанностей (ролей), которые исполнитель по решению или кадровых органов, или менеджера по прикладному функционалу должен выполнять.
Еще одним элементом окружения практически любой функции являются информационные системы, средства которых используются для целей автоматизации учета, контроля, информационного взаимодействия и т. п.
Для представления структуры информационных систем применяются модели типа Application System Type, элементами которых являются выстроенные в иерархическом порядке объекты типа Application System Class (класс прикладной системы), Application System Type (прикладная система), классы информационных сервисов, информационные сервисы, ИТ-функции, классы модулей и модули. Пример модели типа Application System Type приведен на рис. 25. Объекты этой модели имеют многоуровневую детализацию – ассоциации, позволяющие в конечном итоге получить подробное представление об информационной среде функции на модели.
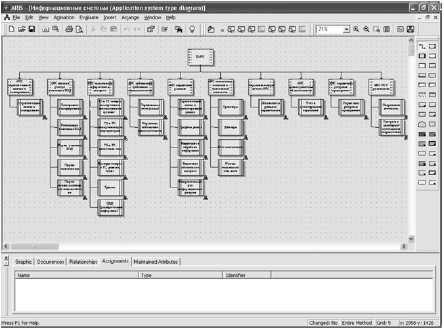
Рис. 25
Создание и подключение библиотек специализированных расчетных алгоритмов (модулей) затрат
Стандартная конфигурация ARIS позволяет производить многие виды стоимостных и прочих затратных (время, ресурсы) расчетов. Опции ABC и Simulation рассчитывают минимальные, максимальные и средние значения затрат многих видов ресурсов. Как уже упоминалось, для того чтобы получить коррелированные данные, надо долго и тщательно готовить модели. Получаемые отчеты очень подробны, содержат много ценной информации, но чтобы из нее выделить нужное, требуется дополнительная обработка отчетов при помощи дополнительных инструментов – как правило, статистического анализа. Однако далеко не всегда пользователь располагает знанием, временем, навыками, необходимыми для выполнения всего комплекса подготовительных и прочих мероприятий. Часто пользователей или интересуют очень специальные данные, которые нерационально долго извлекать, пользуясь стандартным вычислительным аппаратом, или данные выдаются не в том разрезе, который нужен. Для решения узких, специальных задач более рациональным может оказаться создание специализированных расчетных модулей, дающих результат много быстрее и с меньшими издержками. Например, создан скрипт, который выполняет:
? присвоение значений некоторым атрибутам функций типа Times и Cost (максимальные, минимальные или средние значения соответствующих затрат);
? присвоение значений некоторым атрибутам типа Free attributes (специальные расчетные параметры, отсутствующие в стандартной поставке, но интересные для прикладного применения);
? присвоение значений некоторым атрибутам связей между функциями, оргединицами и информационными системами (число работников, процент использования – загрузка различных ресурсов).
Запуск прохождения по модели с указанными атрибутами и расчет с выдачей протокола затрат времени, средств по пройденному «маршруту»
Пример кода, реализующего некоторые из этих действий, приведен в приложении 2. Это функции Function secs(ss As Variant) As Long, Function time_count(sss As Double) As String и процедура Sub Count.
Также создан скрипт, выполняющий расчет зависимости затрат времени и денежных средств от загрузки средств информационной системы при прохождении по специфицированному «маршруту». Будучи выведенным в формате Excel, отчет позволяет получить диаграммы, наглядно показывающие тенденции в использовании тех и или иных информационных систем в бизне^процессах.
Связь между моделью «как есть» и «как должно быть» (независимая база, варианты)
Цели модернизации, актуализации базы, оптимизации процессов предполагают действия по изменению структуры базы, составляющих ее моделей, связанных с моделями объектов и т. п. Базу моделей из состояния «как есть» стремятся перевести в состояние «как будет», «как должно быть» – путем оптимизации процессов по структуре, времени выполнения, порядку распределения ресурсов и т. д. Этого эффекта достигают путем введения дополнительных типов ресурсов, информационных систем и т. п. Оптимизации осуществляются путем применения модуля Simulation. Изменения моделей проводятся, как правило, путем создания копий моделей и последующих их (моделей) модификаций. Копирование моделей производится или вручную, или через механизм «вариантов». Для сохранения унаследованных от моделей-источников связей применяют копирование или «варианты» через использование occurrences моделей и объектов на них. Это сохраняет унаследованные связи. Правда, сразу возникает проблема – изменение объектов модели-приемника сразу же изменяет и модель-источник, что далеко не всегда устраивает разработчика. Приходится копировать модели как Copy
Definitions, это позволяет вносить изменения, не затрагивая модель-источник, но в этом случае – новая проблема – теряются связи объектов. Приходится их восстанавливать вручную, что требует много времени, внимания и чревато ошибками. Были разработаны скрипты, в автоматическом режиме выполняющие функционал копирования моделей с сохранением, где надо, связей.
Один из скриптов уже описан в разделе «Сохранение маршрута модели в виде отдельной модели, связанной с общей базой модели бизнес-архитектуры».
Как известно, Simulation при выполнении может проанализировать только те функции, которые имеют одну и только одну ассоциацию с моделью типа eEpc. Если ассоциаций больше, то процесс Simulation «зависает». Был разработан скрипт, который так корректирует структуру модели, что она (модель) удаляет лишние не нужные для бизнес-процесса связи, сохраняет связи с нужными для бизнес-процесса моделями и источниками данных. Этот скрипт применяется к группе, копируя в целевую группу все модели группы-источника, и дополнительно выполняет следующий функционал:
? в диалоговом режиме запрашивает параметр, определяющий «чувствительность» целевых моделей, например тип транспорта;
? в автоматическом режиме копирует модели группы как Copy Occurrences;
? в цикле для каждой модели проверяет наличие на ней функций, имеющих ассоциации с eEPC-моделями, чувствительными по выбранному параметру, например по типу транспорта;
? при наличии таких функций:
– создается новое definition (определение) функции;
– атрибуты новой функции делаются такими же, как у функции-источника;
– из списка ассоциаций новой функции удаляются ссылки на модели, не удовлетворяющие выбранному параметру (остается только ссылка на модель, имеющая атрибут чувствительности по транспорту, равный выбранному);
– создается новое occurrence (представление) новой функции;
– создаются новые occurrences (представления) связей между occurrence (представлением) новой функции и occurrences (представлениями) объектов, составляющих окружение функции-источника;
– удаляется «старое» occurrence функции на модели.
В итоге автоматически, быстро, очень корректно и безошибочно получаем группу моделей, сохранивших связи с моделями, независимыми от, например, транспорта.
Такие группы моделей после соответствующей подготовки (назначения вероятностей событиям или формирования диаграмм событий, формирования дополнительных моделей, например графиков смен) можно оптимизировать Simulation или анализировать другими стандартными средствами ARIS (ABC или Balanced Scoreboard).
Формирование чувствительности документов
Документы в любом виде – печатном или электронном – представляют собой или элементы нормативной системы, придающей бизнес-процессам легитимность, или элементы оперативной среды, обеспечивающие процедурную, смысловую поддержку бизнес-процессов. Группирование документов на нормативные и оперативные – логичная и повсеместно применяемая практика моделирования бизнес-процессов. Часто бывает оправданной или даже необходимой дальнейшая, более подробная группировка. Например, нормативные документы делятся на законы, приказы, кодексы, распоряжения и т. д., а оперативные – на коммерческие, государственные, ведомственные и т. д. Кроме того, в зависимости от особенностей протекания бизнес-процессов документы должны группироваться по многим другим признакам. Таким образом, становится актуальной проблема – сделать документы «чувствительными» к режимам функционирования, к особенностям протекания бизнес-процессов.
Чтобы сделать документы «чувствительными» к режимам функционирования бизнес-процессов, применяется механизм назначения определенным атрибутам документов специальных значений, закрепленных в Соглашении о моделировании.
Например, значение атрибута документа Identifier= «DOC_NP_*» «делает» документ нормативным, а «DOC_OP_*» – оперативным. Добавление постфикса вместо символа «*» позволяет ввести дополнительную градацию. Например, «PSM» – это письма, а «LAW» – законы и т. д. На рис. 26, 27 приведены примеры применения такой практики к документам.
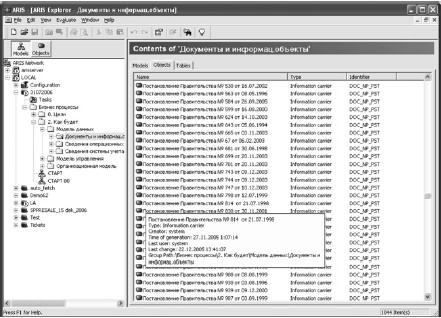
Рис. 26
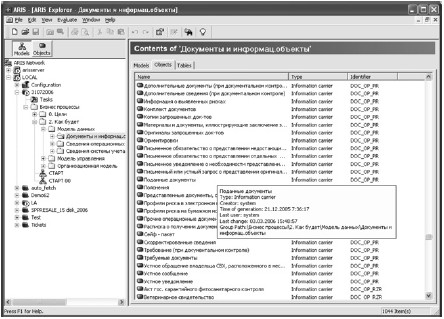
Рис. 27
Для задания чувствительности документов к, например, типу товара, некоему режиму и типу транспорта происходит присвоение атрибутам документа «User attribute Text 1», «User attribute Text 2» и «User attribute Text 3» специальных значений, определенных в «Соглашении о моделировании» в соответствующей, также согласованной нотации. Пример применения этих соглашений приведен на рис. 28.

Рис. 28
В процессе работы специально разработанных скриптов происходит анализ атрибутов документов из окружения функции, и, если совокупность атрибутов документа соответствует совокупности атрибутов, определяемых при выборе входных параметров скрипта (тип товара, таможенный режим, тип транспорта), документ помечается цветом при проходе по модели и его название помещается в выходной отчет.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Читайте также
Программные решения
Программные решения В настоящее время существует множество компьютерных программ, предназначенных для организации цифровых фотографий и обладающих широкими возможностями по созданию тегов. Некоторые распространяются бесплатно, некоторые приходится покупать.
56. Инвестиционные решения
56. Инвестиционные решения Решения в сфере управления инвестициями можно разделить на три блока.I. Отбор и ранжирование. Инвестиционная деятельность осуществляется в различных условиях, и обычно перед инвестором имеется не одна, а по крайней мере несколько возможностей
3.3. Принятие решения
3.3. Принятие решения Решение в ваших руках: вы должны самостоятельно взвесить все «за» и «против» инвестирования за рубеж. Но совет профессиональных финансовых консультантов всегда один: залогом стабильной доходности на долгих периодах является сбалансированный
РЕШЕНИЯ
РЕШЕНИЯ У этих проблем нет простых решений. Искоренить сексуальные преследования полностью крайне трудно. Однако усилия, чтобы справиться с ними, должны быть предприняты, и стоит рассмотреть следующие подходы:1. Издать недвусмысленное заявление генерального
Глава 9 Проектные команды
Глава 9 Проектные команды Оптимист говорит, что стакан наполовину полный, пессимист утверждает, что наполовину пустой, а менеджер проекта считает, что стакан в два раза больше, чем нужно. www.businessballs.com Профессор Крис Стрингер, специалист по происхождению человека и автор
8. Если для решения задачи не хватает какой-то важной информации, продумайте различные возможные сценарии. Вы почти всегда обнаружите, что эта недостающая информация не нужна для решения проблемы
8. Если для решения задачи не хватает какой-то важной информации, продумайте различные возможные сценарии. Вы почти всегда обнаружите, что эта недостающая информация не нужна для решения проблемы Почти всегда то, что мы называем логическими головоломками, использует
Этап 2: мы действительно меняемся! Время формировать проектные команды
Этап 2: мы действительно меняемся! Время формировать проектные команды В то время как на первом этапе происходят изменения в мышлении и методах работы с помощью совместного определения и формулирования операционных ценностей, на этом этапе культурное
Этап 2. Мы меняемся! Проектные команды за работой
Этап 2. Мы меняемся! Проектные команды за работой Если этап 1 направлен на изменение образа мыслей и действий с помощью участия всех заинтересованных лиц в формулировании основных ценностей организации, то на этом этапе изменения касаются отношения к работе, к рабочим
Идеи – это НЕ решения
Идеи – это НЕ решения Самые лучшие в мире идеи никогда не реализуют свой потенциал, пока не будут применены. И самые прекрасные идеи терпят крах именно на стадии
Нестандартные решения
Нестандартные решения ДРК помогает разобраться с причинами проблемы. Это методика разработки прорыва – оригинальных решений, которые опровергают традиционные подходы и ложные предположения – все то, что описывается словами «мы так всегда делаем». Творческий подход
Нестандартные решения
Нестандартные решения Своей гибкостью и потенциалом ДБР обязано именно этому компоненту – нестандартной идее (прорыву). По сути, это некое решение, событие, которого еще не существует в системе, но которое необходимо реализовать, чтобы изменить ситуацию к лучшему.
Решения
Решения P: «Положите ваш материал мне на стол» – это не решение.A: Решение не обязательно должно иметь прецеденты.E: Побочные эффекты ваших решений могут быть опаснее проблемы, которую вы пытаетесь решить.I: Всеобщее одобрение не гарантирует действенности
Поиски решения
Поиски решения P: Решение – это не всегда наращивание прежних показателей. Объемы могут быть урезаны, а курс изменен.A: Не беспокойтесь, что работа будет сделана не надлежащими методами. Она будет выполнена тем методом, каким ее можно сделать. Не рассчитывайте на большее.E:
Глава 7 Чего нужно опасаться при моделировании бизнес-процессов. Проектные риски моделирования бизнеспроцессов
Глава 7 Чего нужно опасаться при моделировании бизнес-процессов. Проектные риски моделирования бизнеспроцессов Моделирование бизнес-процессов следует отнести к группе проектов высокого риска. Стандартные проектные риски касаются выхода за сроки и бюджеты проектов,
Интеграционные решения
Интеграционные решения Специфика постановок задач и реализующих их проектных решений в ряде случаев не может быть эффективно учтена в рамках использования стандартных возможностей ARIS либо «авторских» доработок исполнителя. Принципиально среда ARIS позволяет
Трудные решения
Трудные решения Если в компании проводятся массовые увольнения, а ее высшее руководство получает за это бонусы, то, по словам Шлихтинг, «это подрывает доверие». Когда в трудные времена ее компания была вынуждена заморозить индексацию заработных плат, это коснулось и