Изобилие данных и выбор исследователя
Изобилие данных и выбор исследователя
Это специальный раздел, так что читатель может пропустить его с легким сердцем. Опциональность есть повсюду, и здесь самое место поговорить о предвзятом подходе, или систематической ошибке отбора, вредящей духу науки и делающей избыток данных чрезвычайно опасным для знания. Больше данных – значит больше информации, в том числе неверной. Мы обнаруживаем сейчас, что все меньше исследований повторяют друг друга. Учебники психологии уже следует переписать. Что до экономики – забудьте. Не стоит доверять многим наукам, базирующимся на статистике, – особенно если на ученых давит необходимость публиковаться, чтобы продолжать научную карьеру. Пусть они и утверждают, что «двигают науку вперед».
Вспомним понятие «эпифеномен» и дискуссию о том, чем реальность отличается от библиотеки. Тот, кто изучает историю в библиотеке, обязательно обнаружит куда больше ложных взаимосвязей, чем тот, кто стал участником событий и наблюдает за причинами и следствиями в реальном времени. Нас обманывают эпифеномены, возникающие в том числе из-за переизбытка данных – в сравнении с реальными сигналами.
В главе 7 затрагивался вопрос уровня шума. В сфере информации шум зашкаливает и становится серьезной проблемой, потому что исследователь, как и банкир, обладает опциональностью. Ученый извлекает выгоду, а истина несет убытки. Свобода действий исследователя выражается в том, что он волен выбрать статистику, которая подтверждает его точку зрения – или дает хороший результат, – а остальное утаить. Ученый может попросту остановиться на том результате, который сочтет верным. Более того, он может обнаружить статистические взаимосвязи – и создать иллюзию результата. Таково одно из свойств информации: в огромных массивах данных большие отклонения – это куда чаще шум (или вариации), а не информация (или сигнал)[136].
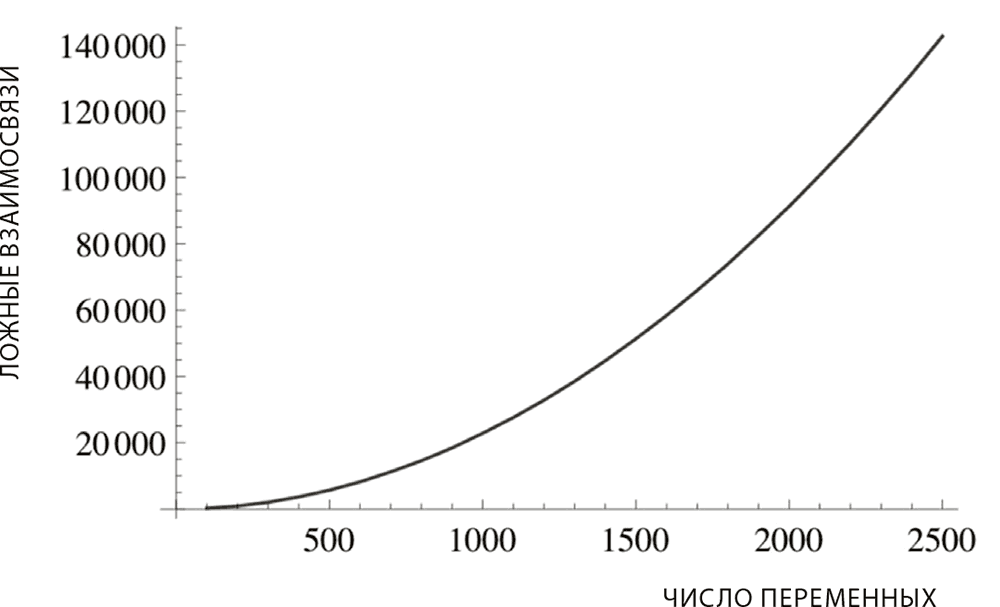
Рис. 18. Трагедия изобилия данных. Чем больше у нас переменных, тем больше взаимосвязей «умелый» исследователь может преподнести как важные. Ошибки нарастают быстрее, чем растет информация; эти ошибки нелинейны (выпуклы) в отношении данных.
В медицине различают два типа исследований: (а) исследование по данным наблюдений, в ходе которого ученый смотрит на статистические соотношения в своем компьютере, и (б) метод двойной анонимности, когда информация добывается в ходе реалистического эксперимента, имитирующего реальность.
Первый тип, наблюдение за данными в компьютере, порождает всевозможные результаты, и, как доказал Джон Иоаннидис, по меньшей мере в восьми случаях из десяти они являются ложными. Однако об исследованиях по данным наблюдений пишутся статьи, публикуемые в некоторых научных журналах. К счастью, такие исследования не одобряет Управление по контролю качества пищевых продуктов и лекарственных препаратов – тамошние ученые очень осторожны. Мы с великим активистом Стэном Янгом, разоблачающим ложную статистику, обнаружили в журнале The New England Journal of Medicine посвященное генетике исследование, результаты которого получены статистическим путем – с тем же успехом их могли взять с потолка. Мы написали в журнал письмо, но нам никто не ответил.
На рис. 18 показано, сколь чудовищно велико может быть число потенциальных ложных взаимосвязей. Идея проста. Если я работаю с набором из 200 случайных переменных, совершенно не зависящих друг от друга, почти невозможно не обнаружить высокую корреляцию на уровне, скажем, 30 процентов, однако эта корреляция будет абсолютно ложной. Есть методики, позволяющие контролировать избирательность (скажем, поправка Бонферрони), но даже они не останавливают злоумышленников – как регулирование не останавливает инсайдеров, которые наживаются на системе. Вот почему за двенадцать с чем-то лет с тех пор, как мы расшифровали геном человека, генетики не добились никаких существенных результатов. Я не говорю, что данные не содержат важной информации; беда в том, что искать ее – все равно что искать иголку в стогу сена.
Искажены могут быть даже сами эксперименты: у исследователя имеется стимул отбирать лишь то, что отвечает его задачам, и скрывать неудачи. Ученый может также сформулировать гипотезу по итогам эксперимента, то есть подогнать ее под эксперимент. Впрочем, тут отклонение не столь велико, как в первом случае.
Эффект «одураченных данными» проявляется все шире. Есть отвратительный феномен «изобилия данных», когда ученые отбирают их в промышленных масштабах. Новое время в избытке обеспечивает нас переменными (и дает слишком мало данных по каждой переменной), так что ложные взаимосвязи множатся куда быстрее истинных, ведь шум обладает выпуклой природой, а важная информация – вогнутой.
По сути, данные могут поставлять нам только знание а-ля via negativa — их можно эффективно использовать для развенчания концепций, а не для подтверждения их.
Трагедия в том, что очень трудно получить финансирование, чтобы воспроизвести – и опровергнуть – уже проведенные исследования. Но даже если деньги найдутся, сложно найти тех, кто за это взялся бы: все понимают, что воспроизводя чужие опыты, героем не стать. В итоге мы не можем доверять эмпирическим результатам – кроме отрицательных. Я романтик, и мой идеал – английский священник, ученый-любитель, который обдумывает опыты за чаем. Нынешние профессиональные исследователи соревнуются в «поиске» взаимосвязей. Наука не должна быть соревнованием; в ней не должно быть табели о рангах – как мы видим, подобная система неизбежно рушится. Нужно очистить знание от агентской проблемы.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Читайте также
Изобилие
Изобилие В то время как Скрудж имел такое состояние, что мог бы ни в чем себе не отказывать, он предпочел жить в нищете. Его денежный сценарий поведения «Не трать деньги ни на себя, ни на других» был настолько силен, что Скруджу стало неудобно даже просто находиться среди
10.1. Изобилие акронимов
10.1. Изобилие акронимов Меморандум о взаимопонимании и согласии, подписанный в марте 1996 года после краха банка Barings на курорте Бока-Ратон 49 биржами и расчетными палатами, показал, насколько фьючерсный и опционный бизнес вырос во всем мире после кризиса
Бескрайнее изобилие
Бескрайнее изобилие «...и отдам тебе хранимые во тьме сокровища и сокрытые богатства, дабы ты познал, что Я Господь».Книга пророка Исайи 45:3Не будьте искателями изобилия, будьте изобилием. Проживите всю свою жизнь в изобилии и не теряйте изобилия, ибо ум имеет склонность
Изобилие здесь и сейчас
Изобилие здесь и сейчас «Сие сказал Я вам, да радость Моя в вас пребудет и радость ваша будет совершенна».Евангелие от Иоанна 15:11«Разве не знаете, что вы храм Божий, и Дух Божий живет в вас?»Первое Послание к Коринфянам 3:18Настоящее - это не часть времени. Настоящее - это
Базы данных
Базы данных Термин «база данных» охватывает широкий круг прикладных программ, которые предназначены для хранения и обработки информации. Многие из них представляют программы в формате, заранее заданном для выполнения каких-то конкретных операций (например ПИС), или
Изобилие источников
Изобилие источников Если вы оратор или спичрайтер, использование цитат дает вам доступ к почти безграничному источнику идей. Цитаты эффективны в начале речи, в конце и в любом другом месте. О чем бы вы ни говорили, можно найти десятки подходящих цитат, если, конечно, знать,
176. Объем и содержание базы данных. Маккей приводил анкету из 66 пунктов. Насколько получение такой подробной информации о клиентах: а) реально; б) необходимо? Внесение данных должно производиться вручную или с применением программного обеспечения? Если программное обеспечение – то какое?
176. Объем и содержание базы данных. Маккей приводил анкету из 66 пунктов. Насколько получение такой подробной информации о клиентах: а) реально; б) необходимо? Внесение данных должно производиться вручную или с применением программного обеспечения? Если программное
Изобилие
Изобилие Чтобы наполнить предприятие более сильным намерением, сосредоточьте свои усилия на четырех главных элементах, которые в конечном счете определяют, как компания создает потребительскую ценность.• Созидание: создание потребительской ценности из чего-то
ОБРАБОТКА ДАННЫХ
ОБРАБОТКА ДАННЫХ Опросные листы, как правило, обрабатывают с помощью программного обеспечения. Его создают в организации или чаще всего предоставляют внешние поставщики. Оно позволяет быстро и с минимальными усилиями собирать данные и анализировать их, представляя как
ПРЕДСТАВЛЕНИЕ ДАННЫХ
ПРЕДСТАВЛЕНИЕ ДАННЫХ Данные могут быть представлены двумя способами.1. Оценки основных тенденций:? среднее арифметическое;? срединное значение – среднее значение в распределении индивидуальных данных; это наиболее широко используемая оценка, поскольку она не
Блаженство в данных
Блаженство в данных Команда Грюневальда внимательно изучает данные о поведении миллионов читателей, чтобы лучше понимать, чего они хотят от приложения. «Через нашу систему проходит огромный поток данных», – говорит Грюневальд. Это позволяет понять, за счет чего можно
Продовольствие: изобилие не там, где в нем есть необходимость
Продовольствие: изобилие не там, где в нем есть необходимость Казалось бы, вполне разумно утверждение, что в мире, где, видимо, имеется изобилие зерна и скота, массовый голод – дело прошлого. Однако голод по-прежнему случается, и не только из-за неурожаев,
Четвертое ага: изобилие – ваше естественное состояние
Четвертое ага: изобилие – ваше естественное состояние Из многого Он взял много, и много осталось. УПАНИШАДЫ Вселенная изобильна. В ней всего всем хватает, а нехватка есть только в мыслях.Бесконечный финансовый достаток ждет каждого из тех, кто придерживается принципов