НАВИГАЦИЯ В ТРУДОВОМ РЫНКЕ
НАВИГАЦИЯ В ТРУДОВОМ РЫНКЕ
Глава, в которой автор выполняет свое обещание и представляет методику анализа рынка труда, доступную каждому
Если вы перепрыгнули сюда, прочитав в первой части главу «Вы на рынке труда», значит, описанные там результаты вам понравились и вы готовы поучиться тому, как это делается, что не может не порадовать автора. Если же вы уже подзабыли, о чем шла речь в той главе, или почему-то пропустили ее, в двух словах напомню.
Мониторинг (отслеживание) рынка труда необходим для управления трудовыми ресурсами, так как без него вы не сможете определить, сколько надо платить своим сотрудникам. А платить надо столько, сколько допускает рынок. Если вы будете платить заведомо «выше» рынка, значит, компания будет терять деньги. Если — «ниже», то ваши сотрудники начнут разбегаться, а у вас останутся в основном те, кто уже и не рассчитывает ни на что большее (а скорее всего, большего и не стоит). Такой мониторинг рынка труда стоит проводить минимум раз в полугодие, так как практика показывает, что именно за этот период рынок может подняться или опуститься в ценах.
Еще один немаловажный результат такого анализа: вы сможете оценить степень соответствия — несоответствия спроса и предложения на рынке. То есть понять, является ли оцениваемая вами вакансия дефицитной: спрос большой, а желающих мало; или, наоборот, предложений много, а спрос невелик. Отсюда вы сможете понять, легко ли вам будет найти специалиста на данную вакансию, или насколько легко трудоустроится ваш сотрудник, желающий поискать лучшей доли.
Сразу хочу предупредить тех читателей, которые знакомы с технологией проведения социологических и маркетинговых исследований: здесь вы найдете для себя мало нового. Однако, насколько я знаю контингент управляющих персоналом, большинство из них таким опытом не обладают. Поэтому я буду рассказывать все до мелких деталей, даже если это будет скучно более осведомленным читателям.
Любое грамотное исследование (кстати, это касается, например, и проведения внутрифирменных анкет и опросов) строится в следующем порядке:
1. Определение целей и задач исследования.
2. Определение технологии его проведения (где и как будем собирать материал, какими способами обрабатывать).
3. Сбор первичных («сырых») данных.
4. Статистическая обработка данных и представление их в виде, удобном для анализа.
5. Анализ и выводы (соответствующие п. 1, то есть целям и задачам исследования).
Ну, с пунктом 1 мы уже справились выше: цели и задачи определены. Теперь будем двигаться далее.
Для начала нам понадобятся несколько важных понятий. Первое из них — это репрезентативная выборка. Вот что это такое.
Мы с вами проводим исследование рынка, то есть поведения огромной массы людей. Идеально было бы, конечно, получить возможность для анализа всего рынка, но это будет крайне трудоемко, да и не нужно. На практике бывает вполне достаточно изучить небольшую его часть, но такую, которая отражает тенденции рынка в целом. Вот эта часть и называется репрезентативной (представительной) выборкой, а рынок в целом, который мы хотим понять, называется генеральной совокупностью.
Правильное определение репрезентативной выборки — главное условие получения достоверного результата исследования. Ошибиться довольно легко. Представьте себе, что вы хотите оценить ценовые ожидания (для рынка труда — это, понятное дело, ожидания уровня оплаты труда) для бухгалтеров. Приходите в ближайшее учебное заведение, готовящее этих специалистов, опрашиваете выпускников. В результате вы получите картину не рынка, а ожиданий неопытных школяров, которые жизни еще не нюхали. Куда же пойти? Ясное дело — на курсы повышения квалификации, где собираются люди, уже отработавшие по нескольку лет.
В курсе статистики иногда приводят такой пример: оказывается, есть прямая зависимость между размером обуви и уровнем интеллекта. Догадались, в чем фокус? Просто измеряли интеллект у всех людей подряд, без учета возраста. Конечно, взрослые (как правило, с большим размером ступни) оказались интеллектуальнее детишек.
Итак, нас интересует рынок труда как генеральная совокупность, и для его анализа нам надо создать репрезентативную выборку. Если бы мы с вами занимались изучением рынка труда с научными целями (например, писали бы диссертацию), все это надо было бы сделать очень строго. Нас же интересует сугубо утилитарный вопрос, поэтому мы сделаем ряд допущений, которые здорово упростят жизнь.
Во-первых, будем считать генеральной совокупностью не весь потенциальный рынок труда, а ту его часть, на которой мы с вами активно действуем, то есть те источники, из которых мы обычно черпаем свои кадры. А зачем брать иные, если мы все равно не собираемся их использовать?
Эти источники — Интернет и газеты, посвященные поиску и предложению работы. Здесь я делаю следующее сильное заявление: можно обойтись Интернетом. Почему? Да потому, что опыт последней пары лет показал, что и там, и в газетах публикуются одни и те же объявления. По крайней мере, это касается наиболее востребованных вакансий (понятно, что уборщиц, грузчиков и слесарей-сантехников в Интернете обычно не ищут, но они нам и не так интересны). Но если специфика вашей компании требует поиска через газеты — нет проблем, от этого технология исследования не изменится.
Заходим на наиболее популярный (или проще — ваш любимый) сайт бесплатных объявлений о поиске и предложении работы. Какой именно? Не скажу, сами должны знать. А теперь сразу открываем программу MS Excel, туда будем записывать результаты. Не забудьте сразу дать имя файлу, например, «рынок бухгалтеров май 02».
Теперь на выбранном нами сайте заходим в режим «поиск работы». Задаем следующие параметры: должность, образование, возраст и пол — в соответствии с требованиями вашей компании. Диапазон оплаты — с хорошим запасом «вниз» и «вверх» . То есть если вы ищете специалиста на 450-500 долларов, то советую задать диапазон от 200 до 1000. Зачем? Чтобы увидеть реальные границы рынка. Теперь срок, за который должен производиться поиск. Я рекомендую от 7 до 10 дней. Почему? Потому, что 1-3 дня — это мало, выборка может получиться недостаточной. Больше — много, потому что в большинстве случаев именно за этот срок человек, активно ищущий работу и обладающий приличными деловыми качествами, обычно ее находит. Так что, задав больший временной диапазон, вы, скорее всего, результаты не улучшите, но сделаете лишнюю работу.
Теперь в открытом нами листе Excel делаем два заголовка: «Спрос» и «Предложение». С чего начнем? Правильно, с предложения, потому что мы находимся на открытом нами сайте в режиме «поиск работы». То есть собираем данные по предложению. То же самое — если вы анализируете объявления в газетах, только там надо найти раздел «Ищу работу».
А дальше прочитываем каждое объявление и записываем в столбик под заголовком «Спрос» те суммы оплаты труда, на которые претендуют соискатели. И так — до конца, то есть до последнего объявления.
Когда закончили — повторяем всю процедуру, но уже в разделе сайта «приглашаем на работу» или с соответствующеи страницей газеты. Вот что у вас получится в конце концов:
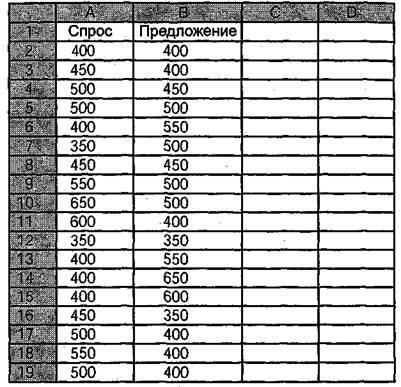
Конечно, здесь нарисована только верхняя часть таблицы: в действительности у вас должно получиться полторы — две сотни записей.
Эта работа по сбору «сырых данных» достаточно простая и механическая, но занимает несколько часов, поэтому лучше поручите ее своим помощникам. Однако первые 3-5 раз проделайте все сами, дабы освоить процедуру и правильно все объяснить.
Тут есть тонкости. Во-первых, старайтесь избегать повторных объявлений. Некоторые соискатели работы настолько нервные, что дают объявление по нескольку раз. Вам эти данные, конечно, не нужны.
Во-вторых, старайтесь не выходить за пределы своего сегмента рынка. Например, вы анализируете рынок труда главных бухгалтеров для средней российской торгово-промышленной компании. Вам наверняка попадутся объявления о поиске главбуха — финансового директора для какой-нибудь корпорации-монстра, владеющей сетью супермаркетов[50], для банка, для иностранной компании. Или, наоборот, какая-то дама ищет работу по совместительству в мелкой фирмешке или у ПБОЮЛа. Это тоже не наш контингент.
Итак, вы получили два столбика цифр: данные по спросу и по предложению на рынке труда. Дальше начинается самое интересное — анализ результатов.
Я полагаю, что читатели в основном знакомы с программой Excel и умеют обращаться с электронными таблицами. Но нам понадобятся некоторые функции этой программы, которые известны далеко не всем, поэтому я расскажу о них подробно.
Мы получили два массива чисел, из которых можно пока сделать только один вывод: сравнить их количество. Если оно примерно одинаково (с разбросом в 10-15%), значит, в целом спрос на рынке труда по анализируемой нами профессии в целом соответствует предложению. Именно в целом, потому что более тонкий анализ может вскрыть интересные несоответствия (см. главу «Вы на рынке труда»). И наоборот, может оказаться, что спрос выше или ниже предложения.
Для начала дадим нашим двум массивам имена: те же самые «спрос» и «предложение». Это нам пригодится в дальнейшем. Если вы не умеете присваивать имена диапазонам клеток в Excel — прочитайте в учебнике или в «хелпе», там все достаточно просто.
Наши два столбика чисел сами по себе ни о чем не говорят: их надо привести в вид, удобный для анализа. Это значит, сделать из них такую таблицу:
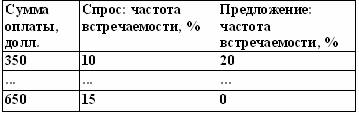
Если вы уверены, что легко и быстро справитесь с этой задачей, то можете смело пропустить следующие 4 страницы. Если нет — советую прочитать, хотя они больше относятся к работе с программой Excel, чем к управлению персоналом.
Для начала отсортируем оба столбика по возрастанию. Это делается совсем просто: в меню «данные» — «сортировка». Теперь мы видим две важные вещи: верхние и нижние границы диапазонов оплаты труда по спросу и по предложению, а также «шаг» их увеличения. В нашем гипотетическом примере диапазон невелик: минимум — 350 долларов, максимум — 650.
В большинстве случаев этот шаг бывает кратным 50 или 100 долларам. Но иногда бывает, что для красоты выборку приходится немного подчистить. Например, если попадаются суммы, скажем, в 170 или 120 долларов. Такие я просто предлагаю округлять в большую или меньшую сторону: нас ведь интересуют тенденции, а не точные значения!
Дальше мы делаем следующее. Создайте на том же листе Excel справа от наших двух столбиков (но отступя несколько столбцов, чтобы не запутаться) массив чисел, содержащий все значения уровней оплаты труда с установленным «шагом» (лучше всего — в 50 долларов). Он должен начинаться с минимального из имеющихся значений и кончаться максимальным. Это будет первая колонка нашей итоговой таблицы «Сумма оплаты, долл.». Можно, конечно, «набить» ее вручную, но проще воспользоваться функцией Excel «автозаполнение». Для этого введите первое и второе числа, например, 100 и 150, затем выделите обе клетки, удерживая пальцем левую клавишу мышки. Вы увидите, что курсор из толстого белого креста превратится в тонкий черный, а в нижнем правом углу выделенного вами диапазона появится маленький квадратик. Установите на него курсор при отпущенной клавише мышки, снова нажмите на клавишу и «протащите» диапазон вниз на десяток клеток. Вот и все! Ваш диапазон заполнился числами с необходимым «шагом». Остается только убрать или добавить снизу (таким же способом) несколько чисел, если вы промахнулись с их количеством.
Теперь нам надо справа от полученного первого столбца нашей итоговой таблицы для каждого значения уровня оплаты труда указать, сколько раз оно встречается среди данных по спросу и по предложению. Можно сделать это тупо вручную, но я предлагаю вам воспользоваться еще одной очень удобной функцией Excel: СЧЁТЕСЛИ.
Эта функция делает вот что: подсчитывает в указанном нами диапазоне количество чисел, совпадающих с определенным числом. То есть именно то, что нам надо!
Делается это так. Установите курсор на ячейку справа от верхней ячейки нашего диапазона уровней оплаты труда. Теперь выберите в меню «вставка» команду «функция» (она также обозначена символом f). Вы открыли экран «мастер функций», состоящий из двух окон. Выберите в левом окне команду «статистические» и в правом — СЧЁТЕСЛИ.
Перед вами появилось окно, куда следует вставить диапазон и условие. Вот тут-то нам и пригодятся имена, присвоенные нашим данным: «спрос» и «предложение». Щелкните мышкой в поле «диапазон», затем выберите в меню «вставка» команду «имя». Появится окно со всеми именами диапазонов, которые есть в нашем листе Excel. Выберите имя «спрос», и оно появится в поле «диапазон». Теперь перейдите в поле «условие» и укажите в нем адрес верхней ячейки диапазона уровней оплаты труда (то есть слева от той, куда вы сейчас вставляете функцию СЧЁТЕСЛИ). Теперь — ОК, и работа закончена, функция вставлена. На экране в этой ячейке вы увидите количество чисел из диапазона «спрос», равных тому, что находится в первой ячейке диапазона уровней оплаты труда. Теперь достаточно скопировать эту ячейку сверху вниз на весь столбец таблицы, и вы получите желаемое.
Тут есть хитрость, которую не все знают. Дело в том, что Excel, копируя ячейки, содержащие функции со ссылками на другие ячейки, по умолчанию использует не абсолютную, а относительную адресацию. Это значит, что в функции СЧЁТЕСЛИ, которую вы скопировали одной ячейкой ниже, адрес ячейки, содержащей условие счета, также окажется на строку ниже, как это нам и надо. Но зато группа ячеек «диапазон» тоже получится не заданной, а на строку ниже! Представляете себе, какие данные вы получите, сделав такую ошибку? Я точно знаю, потому что она типична для всех, кого я обучал своей методике. Поэтому и рекомендую использовать имена диапазонов вместо адресов: они-то уж точно никак не изменятся!
Вот какая табличка у вас получится:

Обратите внимание: в столбцах вашей таблички «Частота, спрос» и «Частота, предложение» (столбцы D и Е) вы видите числа, показывающие, сколько раз соответствующая сумма оплаты (столбец С) встречается в «сырых данных» («Спрос» и «Предложение»). Но если вы выберете курсором любую ячейку в этих столбцах, то сверху, на панели формул, вы увидите что-то вроде «=СЧЁТЕСЛИ (Cпpoc;D3)» или «=СЧЁТЕСЛИ(Предложение;D3)», потому что в действительности в этой ячейке находится не число, а функция «СЧЁТЕСЛИ» с соответствующими адресами аргументов. И если какие-либо данные в столбцах «Спрос» и «Предложение» будут изменены, результаты мгновенно будут пересчитаны! Если хотите, можете проверить.
Наш следующий шаг — пересчитать полученные нами частоты встречаемости в проценты. Для этого сначала подсчитаем суммы по столбцам «Спрос» и «Предложение»; ведь количество данных по этим показателям может быть не одинаковым. Ну, как в Excel считать сумму по столбцам и переводить абсолютные показатели в проценты, вы, наверное, знаете.
Вот что у вас должно получиться в итоге:
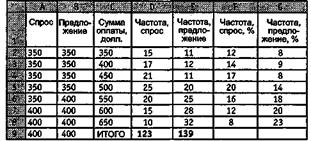
Смотрите: столбцы С, F и G — это и есть итоговая таблица, ради которой мы проделали все предыдущие процедуры! Остальные столбцы нам уже и не нужны. Теперь мы можем привести табличку в окончательный вид, вот такой:
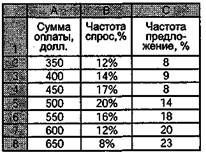
Для тех, кто не очень уверенно работает в Excel, напоминаю: в столбцах «Частота, спрос, %» и «Частота, предложение, %» у вас на самом деле не числа, а формулы для получения процентов! Поэтому если вы просто удалите ненужные столбцы или скопируете нужные в другое место, вы получите в этих ячейках полную белиберду. Следует воспользоваться операцией «копировать — специальная вставка — значения». Тогда вы получите табличку, заполненную не формулами, а числами.
Ну вот, вроде бы все. Осталось только построить график (кто не умеет — читайте учебник). Какой именно график? Лучше всего — диаграмму, то есть столбчатый график. Почему не линейчатый (кривую)? Потому что кривые используются для отражения процессов, например, развивающихся во времени. Здесь же мы имеем ряд дискретных точек (сумм оплаты), и поэтому набор столбиков, отражающих показатели спроса и предложения для каждой из них, будет более точно соответствовать характеру анализируемого нами статистического материала.

Какие выводы можно из него сделать?
Во-первых, рынок труда по анализируемой нами условной профессии в целом примерно равномерен по спросу и предложению (мы нашли 123 объявления о приглашении на работу и 139 — о поиске работы; с точки зрения статистики это не значимое различие).
Во-вторых, диапазон сумм оплаты — от 350 до 650 долларов, то есть весь набор возможных вариантов укладывается между этими суммами в пределах 300 долларов. Теперь мы знаем, что для данной специальности 350-450 долларов — это «невысокая» зарплата, 450-550 долларов — «средняя», а свыше 550 — «высокая».
В-третьих, в диапазоне от минимума (350 долл.) до 500 долларов спрос постоянно превышает предложение, то есть больше половины работодателей (в сумме — 63%) готовы платить относительно «низкую» или «среднюю» по рынку зарплату. В то же время на этот уровень оплаты труда согласны всего 39% соискателей, а остальные 61% оценивают свой трудовой ресурс более высоко.
В-четвертых, 43% соискателей (близко к половине!) претендуют на 600-650 долларов, а готовы платить эту сумму всего 20% работодателей.
Какая тактика подбора персонала следует из обнаруженной нами ситуации на рынке труда? Очевидно, что если мы захотим сэкономить и будем искать специалистов в «нижнем» диапазоне оплаты, то нам придется повозиться, так как спрос здесь значительно превышает предложение. Если мы, наоборот, захотим «снять сливки» с рынка труда и заявим сумму 600-650 долларов, то достаточно легко и быстро заполним вакансию, так как предложение в этом диапазоне намного выше спроса. Но при этом мы оставим своему сотруднику сравнительно небольшую перспективу для роста, что не особенно хорошо. В такой ситуации я бы предложил 500 долларов с перспективой до 600: здесь и предложение есть, и возможности для роста.
Вот, собственно, и все. Теперь предлагаю в качестве упражнения проанализировать по этой методике рынок по позиции «менеджер по персоналу». Вдруг «по рынку» вы заслуживаете большего?
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Пинбол на рынке
Пинбол на рынке Полезный с точки зрения торговой психологии опыт я приобрел, когда, будучи студентом колледжа, проводил время за игрой в пинбол на автоматах. В целом я был весьма посредственным игроком. Несколько шаров мог удерживать в игре довольно долго, а остальные
Ситуация на рынке
Ситуация на рынке Процесс продажи или покупки подержанных машин все еще строится преимущественно на частной основе, а потому крайне хаотичен и криминализирован. Анализ выявил следующие тенденции:• стремительное увеличение парка автомобилей иностранного
Место на рынке
Место на рынке В мировой практике независимым называют автосервис, не входящий в официальные дилерские сети автопроизводителей и не находящийся в составе предприятий с крупными автопарками. Главным конкурентным преимуществом независимых автосервисов является их
Эйфория на рынке
Эйфория на рынке Если кому-либо требуется классический учебный пример воздействия на психологию рынка, ему следует заняться изучением событий конца прошлого – начала нынешнего столетий. Конец 90-х годов совершенно беспрецедентен в плане масштабов наработанного и
Пример 19. Расходы на доплату за работу в ночное время учтены в целях налогообложения прибыли при отсутствии данного условия в трудовом договоре с работником
Пример 19. Расходы на доплату за работу в ночное время учтены в целях налогообложения прибыли при отсутствии данного условия в трудовом договоре с работником Организации, в которых применяется многосменный режим работы, должны устанавливать доплату в ночное время с
Риск на рынке
Риск на рынке Мы уже говорили о том, что риск влияет на требования к уровню дохода, которые предъявляют к своим вложениям потенциальные инвесторы. А что такое риск в понимании финансов и рынка ценных бумаг? Риск в финансах – это возможные колебания прибыльности вложений.
Как утвердиться на рынке
Как утвердиться на рынке Брэд утвердился на рынке благодаря тому, что предоставлял своим клиентам услуги высокого качества. К тому же он завоевал репутацию надежного, пунктуального и трудолюбивого человека. В результате его клиенты не только обращались к нему снова и
1.5.1.2. Навигация по клубам
1.5.1.2. Навигация по клубам Следующий за предварительной агрегацией шаг — непосредственно сбор потенциальных участников. Зададимся вопросом, как человек узнает о клубах? Прежде чем затевать что-либо самому, стоит выяснить, не проще ли присоединиться к тому, что уже
11.3.3. Определение объема спроса на фактор производства фирмой, являющейся монополистом на товарном рынке и совершенным конкурентом на рынке факторов
11.3.3. Определение объема спроса на фактор производства фирмой, являющейся монополистом на товарном рынке и совершенным конкурентом на рынке факторов Построение рыночной кривой спроса на труд со стороны предприятий, обладающих монопольной властью на товарном рынке, в
ВЫ НА РЫНКЕ ТРУДА
ВЫ НА РЫНКЕ ТРУДА Глава, где автор делает краткое введение в маркетинг, а заодно демонстрирует несколько графиков с объяснением, что они означают. В конце же затевает интрижку с читателем и дает ему домашнее заданиеЕсли мы согласились, что с экономической точки зрения
НЕРЕЗИДЕНТЫ НА РЫНКЕ ГКО
НЕРЕЗИДЕНТЫ НА РЫНКЕ ГКО Очень часто приходится слышать, что в российском кризисе «виноваты» иностранные инвесторы, нерезиденты, которые «завалили» рынок ГКО, и Центральный банк, который разрешил иностранцам вкладывать свои средства в российские ценные бумаги.
Страх на b2b рынке
Страх на b2b рынке Давайте рассмотрим начальника отдела снабжения, прораба или менеджера среднего звена. Другими словами, человека, который принимает решения об оптовых закупках, например, материалов для строительства.В дополнение к графикам, логике, фактам и цифрам есть
Информация о рынке
Информация о рынке Маркетинговое исследование представляет собой процесс сбора информации с помощью опросов, углубленных интервью, наблюдений, дискуссий в фокус-группах, анализа результатов первичных и вторичных исследований, проводившихся при разработке
Навигация в мире капитала
Навигация в мире капитала По сравнению с коммерческими собратьями социальные предприниматели, с одной стороны, имеют более широкий набор вариантов для финансирования, с другой – обязаны решать ряд уникальных задач. Как правило, у социальных предпринимателей было два не
Навигация: как сделать так, чтобы клиенты не заблудились
Навигация: как сделать так, чтобы клиенты не заблудились Когда вы выбрали себе офис, очень важно сделать его легко находимым. С этим зачастую возникает проблема у многих агентств. Владельцы агентств почему-то думают, что если они могут добраться с утра на работу, то так же