Как жирные хвосты (Крайнестан) возникают из-за нелинейных реакций на параметры модели
Как жирные хвосты (Крайнестан) возникают из-за нелинейных реакций на параметры модели
У редких событий есть особенное свойство, которое сейчас никем не учитывается. Мы работаем с ними, используя модель, математический механизм: на входе в него закладываются параметры, а на выходе получается вероятность. Чем меньше у нас уверенности в точном значении параметров для подобных моделей, тем больше мы склонны недооценивать маленькие вероятности. Проще говоря, маленькие вероятности выпуклы в отношении ошибочных вычислений точно так же, как полет на самолете вогнут в отношении ошибок и пертурбаций (как мы помним, самолеты опаздывают, а не прилетают раньше срока). При этом чем больше источников пертурбаций мы забываем учесть, тем дольше будет лететь самолет по сравнению с нашей наивной оценкой времени в полете.
Все мы знаем: чтобы вычислить вероятность, используя стандартное нормальное статистическое распределение, нам нужен параметр «среднеквадратическое отклонение» – или что-то подобное, характеризующее масштаб или дисперсию значений величины. Неопределенность в среднеквадратическом отклонении существенно влияет на малые вероятности. Так, для отклонения «три сигмы» вероятность события, которое должно случаться не чаще, чем один раз на 740 наблюдений, повышается на 60 процентов, если среднеквадратическое отклонение увеличивается на пять процентов, и падает на 40 процентов, если среднеквадратическое отклонение уменьшается на те же пять процентов. И если вы ошибаетесь в среднем на пять процентов, наивная модель выдаст оценку, заниженную примерно на 20 процентов. Асимметрия огромна, но лиха беда начало. Все становится совсем плохо, когда мы берем другие отклонения, скажем, «шесть сигм» (увы, в экономической науке эти «шесть сигм» встречаются сплошь и рядом): ошибка возрастает в пять раз. Чем реже событие (т. е. чем больше «сигма»), тем сильнее влияет маленькая неопределенность параметров на конечный результат. С событиями вроде «десять сигм» результаты отличаются в миллиард раз. Этот довод показывает, что меньшие вероятности требуют большей точности вычислений. Чем меньше вероятность, тем больше маленькое, чрезвычайно маленькое округление в расчете влияет на него так, что асимметрия становится абсолютно несущественной. Для расчета крошечных, совсем крошечных вероятностей вам нужна почти бесконечная точность в оценке параметров; малейшая неопределенность приведет к чудовищной катастрофе. Эти вероятности очень выпуклы в отношении возмущений. При помощи данного рассуждения я некогда доказывал, что маленькие вероятности невычислимы, даже если у нас есть работающая модель, а ее у нас, конечно же, нет.
Все то же самое относится к непараметрическому вычислению вероятностей по наблюдавшейся частоте. Если вероятность близка к 1/объем выборки, возникающая погрешность чудовищна.
Вот в чем ошибка «Фукусимы». Вот в чем ошибка Fannie Mae. Подытожим: маленькие вероятности растут тем быстрее, чем больше меняется параметр, который используется при вычислении.
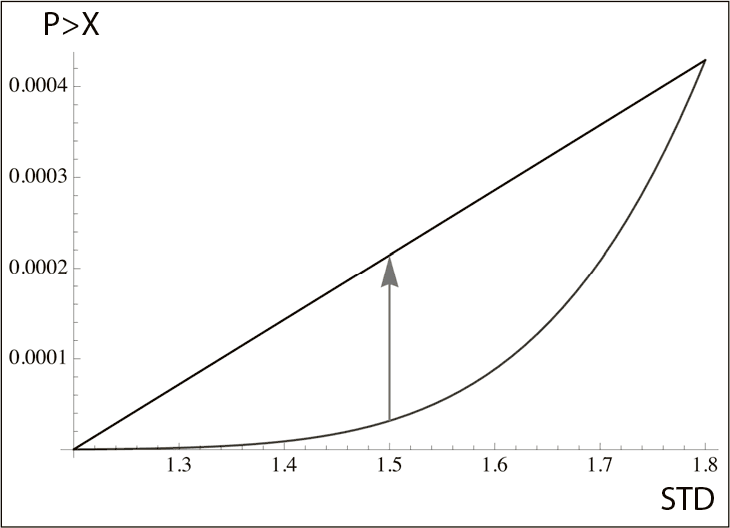
Рис. 38. В гауссовой модели вероятность выпукла в отношении среднеквадратического отклонения. График показывает, как среднеквадратическое отклонение (STD) влияет на вероятность P>x и сравнивает две ситуации: P>6 при STD, равном 1,5, и P>6 при линейной взаимосвязи в промежутке между 1,2 и 1,8 (здесь a (1) = 1/5).
Плохо то, что возмущение ? затрагивает в том числе хвост распределения, причем выпукло; риск портфеля, который чувствителен к хвостам, возрастает при этом неимоверно. Мы все еще в гауссовом пространстве! Подобная взрывоопасная неопределенность возникает не из-за естественных жирных хвостов в распределении, а вследствие маленькой неточности в оценке параметра. Это эпистемическое явление! Вот почему люди, использующие такие модели, зная, что оценка параметров неточна, неизбежно и жестоко противоречат сами себе[139].
Разумеется, неопределенность становится еще опаснее, когда на переменчивые хвостовые экспоненты мы накладываем не-гауссову реальность. Даже при степенном распределении результат ужасен, особенно при изменении хвостовой экспоненты, когда последствия станут просто катастрофическими. Так что жирные хвосты означают невычислимость хвостовых событий – и не более того.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Читайте также
Глава 31 Миром правят толстые хвосты Толстые хвосты и инвестирование
Глава 31 Миром правят толстые хвосты Толстые хвосты и инвестирование [Виктор Нидерхоффер] рассматривал рынки как казино, где люди действуют подобно игрокам, а их поведение может быть понято путем наблюдения за игроками. Он регулярно зарабатывал небольшие суммы, действуя
Сногсшибательные хвосты
Сногсшибательные хвосты Нормальное распределение – краеугольный камень в финансовой науке, включая модели случайных блужданий, ценообразования на финансовые активы, оценки инвестиционных рисков (VaR-модели) и модель Блэка-Шоулза.Возьмем VaR-модели, которые пытаются
Что означают толстые хвосты для инвесторов?
Что означают толстые хвосты для инвесторов? О’кей: значительные изменения цен случаются чаще, чем предполагалось. Но что это значит для инвесторов с практической точки зрения? Я вижу здесь несколько важных моментов:• Причинно-следственное мышление. Одно из основных
Глава 8. Хвосты кенгуру
Глава 8. Хвосты кенгуру Обнаружив себя на стороне большинства, знайте - пришла пора реформ. Марк Твен (Mark Twain) Хвост кенгуру считается чрезвычайно мощным катализатором. Для голого трейдера это явный признак того, что рынок зашел слишком далеко. Много трейдеров по всему миру
Длинные хвосты кенгуру
Длинные хвосты кенгуру В большинстве случаев хвосты кенгуру украшают тела длинных свечей. Это означает, что длина хвостов чуть превышает размеры ближайших свечей. Длинные хвосты кенгуру присоединены к крошечным телам. Посмотрите на хвост кенгуру, сформировавшийся на
Урок 4. «Подчищаем хвосты»
Урок 4. «Подчищаем хвосты» За прошлые три занятия была сделана большая часть работы. Сегодня маленькое занятие, которое в первую очередь касается тех, у кого общая сумма трат превысила 90 % от дохода.Задание 4. Выпишите категории трат в порядке приоритетности. То есть, от
§5. Хвосты или медвежьи ловушки
§5. Хвосты или медвежьи ловушки Представьте, что вы нашли акции с очень устойчивым уровнем поддержки, например, 20 долларов. Верхняя граница колебаний может случайно меняться или быть такой же великолепно надежной, т.е. обе границы определены очень четко. И вдруг вы
89. Модели детерминированного факторного анализа и аддитивные модели
89. Модели детерминированного факторного анализа и аддитивные модели Детерминированное моделирование факторных систем – простое и эффективное средство формализации связи экономических показателей. Оно служит основой для количественной оценки роли отдельных
Примеры реакций на возражения
Примеры реакций на возражения Многолетняя практика работы экспертов Агентон позволила выявить закономерность возражений, фраз, которые клиенты часто произносят в телефонных разговорах. Агенты партнеры системы Агентон учат ответы на возражения наизусть. Те эксперты,
4.3.4. Классификация реакций
4.3.4. Классификация реакций Табл. 4.3.7 даёт классификацию реакций. На сегодняшний момент на большинстве фирм доминирующим оказывается один определённый тип реакции. Это обычно происходит на тех фирмах, которые выросли в своей основной зоне хозяйствования, а потом либо
АНАЛИЗ СОБСТВЕННЫХ РЕАКЦИЙ
АНАЛИЗ СОБСТВЕННЫХ РЕАКЦИЙ Наряду с необходимостью анализа взаимоотношений с другими людьми для определения направлений своего личностного роста важен и анализ собственных реакций на те или иные раздражители. Ведь для того, чтобы научиться управлять своими эмоциями,
Идея № 97 Как возникают мифы об управлении
Идея № 97 Как возникают мифы об управлении * * *Эффект Готорна – одно из наиболее часто цитируемых исследований управления – совсем не то, чем
Подчищаем хвосты и играем в теннис
Подчищаем хвосты и играем в теннис Теперь поговорим о том, как действовать дальше, что делать завтра. Завтра мы завершаем рабочую неделю, и ваша задача — закрыть как можно больше дел, которые вы начали в течение ее первых дней.Если же какие-то дела закрыть не получится, то
Привычки не возникают, они вырабатываются
Привычки не возникают, они вырабатываются Привычки похожи на жемчуг. Натуральные жемчужины вырастают в раковинах устриц, слой за слоем, на протяжении нескольких лет. Но почему на перламутре вдруг начинает формироваться жемчужина? Триггером для организма устрицы
Используйте силу отказа от реакций
Используйте силу отказа от реакций Один из самых сильных приемов в подобной ситуации – полный отказ от реакций. Как-то поздно вечером я встречался с президентом Чавесом и членами его кабинета. Президент был в ярости на политическую оппозицию. Целый час он изливал на меня
Сохранение маршрута модели в виде отдельной модели, связанной с общей базой модели бизнес-архитектуры
Сохранение маршрута модели в виде отдельной модели, связанной с общей базой модели бизнес-архитектуры Для того чтобы применить некоторые стандартные средства ARIS (например, стоимостной, временной анализ, симуляцию и т. п.) к моделям, их нужно предварительно готовить, как