Глава 15 Динамика управления рисками
Глава 15
Динамика управления рисками
Несмотря на неоднократно повторявшиеся утверждения, что управление рисками должно быть постоянной деятельностью, у вас могло все же остаться ощущение, что им по-настоящему занимаются в начале проекта, а затем (не считая эпизодического пустословия) спокойно забывают о нем до следующего проекта.
Возможно, так могли бы решать проблемы управления рисками существа, наделенные даром абсолютного предвидения, но не мы. Когда проекты проваливаются, то часто это происходит примерно на середине, поэтому именно в это период управление рисками нужно проводить особенно активно. Причины проблем почти всегда возникают еще раньше, но их осознание приходит примерно на середине проекта: на начальной стадии проекта дело кажется идущим без помех, а затем все разваливается. Эту стадию проекта можно назвать «Возмездие»: к нам возвращаются наши прошлые грехи, включая плохое планирование, пропущенные задачи, плохо построенные отношения, скрытые допущения, излишнюю надежду на везение и т.п.
В этой главе мы рассмотрим роль управления рисками в период Возмездия и далее, вплоть до конца проекта.
Управление рисками, начиная с периода Возмездия
Вот наш краткий список мер по управлению рисками, которые нужно осуществлять в период с середины проекта и далее, до самого конца:
1. непрерывный мониторинг показателей наступления рисков в поисках такого риска из списка, который кажется готовым перейти из разряда «всего лишь скверной возможности» в разряд «реальных проблем»
2. продолжение выявления рисков
3. сбор данных для наполнения хранилища рисков (базы данных для определения количественного влияния проблем, наблюдавшихся в прошлом)
4. ежедневное отслеживание показателей завершенности (см. ниже)
Пункты 1 и 2 были рассмотрены в главах 9 и 14, и здесь мы к ним не будем возвращаться. Пункты 3 и 4 относятся к системе показателей: количественным показателям размера, целей и содержания, сложности и состояния проекта. Эти показатели и будут предметом этой и следующей глав.
Показатели завершенности
Мы используем здесь термин «показатели завершенности» но отношению к определенному классу показателей состояния, показывающему состояние исполнения проекта. Совершенная система показателей завершенности (если только такие существуют) уверенно покажет, что выполнено 0% в начале проекта и 100% в конце успешно завершенного проекта. А между ними она будет показывать постепенно возрастающие величины от 0 до 100. В лучшем из миров анализ после завершения проекта приведет к выводу, что значения безупречной системы показателей на каждой стадии проекта точно и ясно предсказывали, сколько еще остается времени и усилий.
Понятно, что совершенных систем показателей завершенности не бывает, но существуют несовершенные, которые невероятно полезны. Мы – сторонники двух из них:
• завершение описания граничных условий проекта
• освоенный объем функционала (ООФ)[26]
Эти показатели дают нам способ отслеживать пять главных рисков, рассмотренных в главе 13. Первая система защищает от главного риска, состоящего в нарушении спецификаций. Вторая представляет собой общий показатель чистого прогресса, используемый для отслеживания влияния остальных четырех главных рисков.
Завершение описания граничных условий проекта
Система – это нечто, предназначенное для преобразования входов в выходы, как показано на следующей диаграмме:
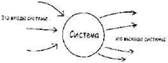
Это – правильное описание, будь система, о которой идет речь, государственным ведомством, бухгалтерской компанией, типичной IT-системой, живым человеком или селезенкой… то есть чем бы то ни было, что мы склонны назвать словом «система».
В этом смысле у IT-систем есть отличие: они преобразуют потоки входных данных в потоки выходных данных. Традиционно задача спецификации таких систем сводилась почти полностью к определению правил преобразования, методики и подходов, применяемых системой при преобразовании входных потоков в выходные. Часто в процессе спецификации пропускают строгое и подробное описание самих потоков. Этот пропуск имеет некоторые непреодолимые причины: работа по определению этих потоков часто рассматривается как задача проектирования, которую программисты будут решать на более поздних стадиях. Она может оказаться очень затратной по времени. Откладывание полного определения разумно в проектах, где можно быть уверенными в успешном завершении проекта, но есть ведь и менее везучие проекты, где подробное определение потоков невозможно успешно провести, поскольку это вызовет обострение некоторых конфликтов среди участников проекта. Существование таких «дефективных» проектов вынуждает нас запихивать работу по описанию потоков обратно на раннюю стадию жизненного цикла с намерением заставить конфликт всплыть на поверхность пораньше, не позволяя ему оказаться замазанным на начальных стадиях и неожиданно появиться позднее.
При этом подходе граничные потоки определены, но не спроектированы. Под этим мы подразумеваем, что они разложены до уровня элементов данных, но еще не упакованы в какой-то формат. Цель раннего обращения к проблеме состоит в том, чтобы все стороны согласились с составом потоков. В большинстве проектов такое согласие удается получить в пределах первых 15% времени работы над проектом. Когда согласие еще не достигнуто, а проект явно прошел 15%-ную отметку, то это с очевидностью указывает на то, что существует либо конфликт между участниками проекта (нет единого мнения о том, какую систему строить), либо прискорбная ошибка в оценке длительности проекта. В любом случае отсутствие согласия представляет собой проявление риска, причем одного из главных. Нет смысла работать над чем-то другим, пока не будет завершено описание граничных элементов. Если этого не произойдет, нет лучшего выбора, чем прекращение проекта.
ООФ (первый проход)
Освоенный объем функционала – это система показателей готовности проекта. Она должна говорить вам, насколько далеко вы продвинулись по пути от 0% готовности к 100% готовности.
Поскольку ООФ тесно связан с инкрементной разработкой проекта[27], мы решили отложить подробное определение этой метрики до обсуждения метода инкрементной разработки в следующей главе. На этапе первого прохода мы покажем только основное назначение этой системы и ее отношение к инкрементному плану проекта.
Допустим, что мы заглянули внутрь системы, которую вы намереваетесь построить, и изображаем ее разбитой примерно на сотню основных частей:
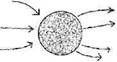
Если вы теперь начнете строить систему просто по методу «большого взрыва» (строить все эти части, соединять и тестировать их, поставлять их все вместе, когда все будут готовы), то вашей единственной метрикой готовности будет окончательная проверка при приеме проекта в целом. В виде функции от времени ваша показанная готовность будет выглядеть так:
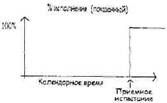
Вы проявляете 0%-ную готовность до самого конца, а затем внезапно она сменяется 100%-ной готовностью. Единственной причиной верить, что дело обстоит иначе (скажем, верить в некоторый момент, что вы находитесь в состоянии 50%-ной готовности), являются косвенные признаки.
ООФ предназначен для обеспечения объективными свидетельствами частичной готовности, которые позволят вам нарисовать такую картинку и поверить в нее:
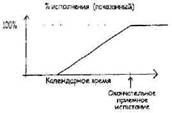
Все равно будет период на начальной стадии, когда прогресс подтверждается только верой. Однако уже намного раньше середины проекта, вы будете получать довольно надежные свидетельства от ООФ о частичной готовности.
ООФ зависит от вашей способности строить систему методом инкрементной разработки, скажем, используя выбранные подсистемы, составленные из частей системы и называемые версиями. Так, версия 1, например, может быть такой:
Здесь вы соединяете (как можно лучше) входящие <……> частичным продуктом. Разумеется, частичная система <……> все, что должна делать полная система, но что-то <……> можно тестировать. Итак, вы это тестируете. Вы проводите испытания версии 1 и, когда она их проходит, вы заявляете <……>
Версия 2 имеет больше функций:
Версия – % от общего ООФ
1 – 11%
2 – 19%
3 – 28%
4 – 38%
5 – 51%
6 – 60%
7 – 72%
8 – 81%
9 – 94%
10 – 100%
Теперь с момента, когда версия 1 проходит свои приемные испытания (ПИ1), вы можете построить кривую, показывающую ожидаемую дату каждого следующего приемного испытания (ПИ)[28]. По мере прохождения этих испытаний можно в такой форме проследить ожидаемый ООФ и соотнести его с реальным:

Проявление любого из главных рисков (или какого-то еще серьезного риска) вызовет заметное отставание реального завершения версий от ожидаемого.
Приведенный здесь пример явно вымышленный, но при выборе чисел и формы графика реального завершения, сравниваемого с ожидаемым, мы старались дать вам представление о примерном уровне контроля, обеспечиваемого этой схемой.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
2. Роль органов управления в системе управления рисками
2. Роль органов управления в системе управления рисками В передовых организациях управление рисками встроено естественным образом в систему принятия решений на всех уровнях: от совета директоров до рядового работника.В соответствии с лучшей практикой совет директоров
4. Внедрение системы управления рисками
4. Внедрение системы управления рисками Уровень развития системы управления рисками, безусловно, зависит от размера компании, отрасли, стадии развития и пр. В общем виде этапы внедрения системы управления рисками можно представить таким образом:1. Назначение
Приложение 1 Процесс управления рисками
Приложение 1 Процесс управления рисками
5.2. Адаптация управления банковскими рисками
5.2. Адаптация управления банковскими рисками Внедрение ТЭБ оказывается, как показывает практика, весьма нетривиальной задачей, которая хотя и имеет известные решения, но во многом отличается от базовой задачи автоматизации банковской деятельности, давно уже ставшей
88. Основы управления банковскими рисками
1. Происхождение и сущность банков Происхождение современного банка – результат длительной исторической эволюции. Первыми коммерческими банками считаются храмы, которые использовались для хранения денег и товаров. Стабильность храмового хозяйства способствовала
Глава 2 Обзор существующих стандартов и методологий управления рисками
Глава 2 Обзор существующих стандартов и методологий управления рисками 2.1. Зачем нужны стандарты и методологии управления рисками Выбор адекватных методологий управления рисками, моделей ЖЦ ПО, метрик ИТ-проектов, использования инструментальных средств и разработки ПО
8.1. Сущность управления рисками
8.1. Сущность управления рисками Динамизм изменчивости условий, в которых работают фирмы, открывает для них множество возможностей, но одновременно обусловливает ряд сложных и многообразных проблем, которые нельзя решить при традиционных подходах к менеджменту
85. Матрица управления рисками
85. Матрица управления рисками Инструмент«Риск возникает из-за незнания того, что вы делаете», – заявил Уоррен Баффетт.Еще одной альтернативой диаграмме «Солнца и тучи» является матрица управления рисками, хотя, как и в случае с обобщенным индексом риска
Глава 4 Доводы в пользу управления рисками
Глава 4 Доводы в пользу управления рисками Ни один план не выдерживает боевого столкновения с противником фельдмаршал Гельмут фон Мольтке На примере ДМА следует осознать, как велики потенциальные затраты, вызванные тем, что рисками не управляют. Если предыдущая глава
Глава 5 Доводы против управления рисками
Глава 5 Доводы против управления рисками Управление рисками часто показывает вам больше реальности, чем вам хочется. Майк Эванс (MikeEvans), первый вице-президент корпорации АSC[14] Следует признать, что есть несколько причин не прибегать к управлению рисками. Мы не стали бы
Глава 9 Механика управления рисками
Глава 9 Механика управления рисками Мы совсем неплохо оцениваем. Нам просто плохо удается перечислять все допущения, лежащие в основе наших оценок. Поль Рук[17] Вот простая проверка осведомленности о рисках в проекте: просмотрите план проекта и попросите руководителя
Глава 10 Правила управления рисками
Глава 10 Правила управления рисками Осталось описать только детали. В предыдущих главах было уделено достаточно внимания основным представлениям, поэтому уже можно перейти к изложению общих правил того, что понимают под управлением рисками.Что понимают под управлением
Глава 22 Уточнение правил управления рисками
Глава 22 Уточнение правил управления рисками Вернемся к правилам, впервые изложенным в главе 10, чтобы добавить некоторые уточнения. Начнем здесь с пересмотра первого раздела этой главы «Что понимают под управлением рисками».Что понимают под управлением рисками