Шаг 3. Моделирование (выбор факторов)
Модель – это преднамеренно упрощенное представление определенного события или ситуации. Термин «преднамеренно» означает, что модель разрабатывается специально для решения конкретной проблемы. Термин «упрощенно» говорит о том, что следует исключить из рассмотрения все банальные и несущественные детали, выделив важные, полезные и ключевые особенности, определяющие специфику проблемы. Проиллюстрируем процедуру выбора факторов на примере.
3. Моделирование

Модель можно сравнить с карикатурой. Она заостряет внимание на некоторых чертах – носе, улыбке, кудрях, – и на их фоне другие черты теряют выразительность. Хорошая карикатура отличается тем, что отдельные черты выбираются обдуманно и эффективно. Точно так же модель акцентирует внимание на отдельных особенностях реального мира. При построении любой модели вам придется действовать избирательно. Нужно выбрать именно те особенности, которые имеют отношение к решению вашей проблемы, и пренебречь остальными. Модель носит схематичный характер, чтобы помочь пользователю сфокусироваться на исследуемой проблеме[26].
Отсюда следует, что модели не могут быть абсолютно корректными. Знаменитый статистик Джордж Бокс как-то заметил, что «…все модели некорректны, но некоторые при этом полезны»[27]. Ключевая проблема в том, чтобы определить, когда модель приносит пользу, а когда она некорректна настолько, что искажает реальность. В главе 5 мы подробнее поговорим об этом. А пока заметим, что одним из ключевых является вопрос о выборе факторов для включения в модель.
Каким образом отбираются факторы для модели и прогнозируются их взаимосвязи? По большей части мы в этом вопросе руководствуемся субъективными соображениями. Гипотеза, то есть априори разработанная концепция анализа, представляет собой не более чем наукообразные предположения о том, какие факторы имеют наибольшее значение в каждом конкретном случае. На этом этапе разработка модели требует логического мышления, опыта и знакомства с предшествующими исследованиями. Только в этом случае можно с большой долей уверенности предположить, какие зависимые (те, которые нужно прогнозировать или объяснить) или независимые факторы сыграют основную роль. Можно попытаться протестировать модель – именно это отличает аналитическое мышление от менее точных методов принятия решений вроде интуиции.
Например, если вы социолог и пытаетесь прогнозировать динамику дохода семьи (зависимая переменная), то можно предположить, что независимыми переменными в вашей модели будут возраст, образование, семейный статус и количество работающих постоянно членов семьи. Именно эти переменные имеют смысл при прогнозировании семейного дохода. Впоследствии, в процессе количественного анализа (а точнее, на этапе анализа данных) вы можете обнаружить, что модель недостаточно точно отражает реальную ситуацию, и захотите пересмотреть состав переменных при условии, что по новым переменным можно получить данные.
Даже очень субъективные модели и переменные могут быть полезны для уточнения проблемы. Например, Гарт Сандем, известный популяризатор науки, математики, юморист и писатель на темы гик-культуры, многие жизненные проблемы решал путем анализа субъективно отобранных, но все равно полезных переменных[28]. В частности, так он подходил к решению вопроса о том, какое именно домашнее животное лучше выбрать и стоит ли его заводить вообще.
Какие переменные человек принимает во внимание, решая, заводить ли домашнее животное? Сандем отобрал следующие:
• Постоянная жизненная потребность в любви (D, 1–10, где 10 баллам соответствует жизнь как у начальника тюрьмы днем и честного налогоплательщика ночью).
• Общий уровень ответственности (R, 1–10, где 1 балл соответствует убежденности в том, что «дети, налоговый инспектор и дела как-нибудь сами устроятся, если оставить их в покое»).
• Наиболее продолжительная поездка в последние шесть месяцев (T, дней).
• Продолжительность сверхурочных (H, часов в день).
• Ваша терпимость к проделкам других существ (M, 1–10, где 1 балл означает, что вы ведете себя как Стервелла де Виль, а 10 баллов – как доктор Дулиттл).
• Насколько вы заботливы (N, 1–10, где 1 балл означает «мой кактус засох»).
Все эти переменные весьма субъективны, но они, по всей видимости, полезны и, уж конечно, забавны. Сандем вывел следующее уравнение (выглядит довольно устрашающе!), где обобщающим показателем является Fido – индекс готовности к заведению домашнего питомца:
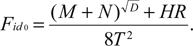
Наиболее важной переменной в этом уравнении является D – потребность в любви, которая прямо пропорционально связана с результирующим показателем. Неплохо также, если у вас есть немного свободного времени (H), чтобы проводить его с питомцем, и вы ответственный человек (R). Эти две переменные также прямо пропорционально влияют на Fido. Но если вам приходится много ездить, значение вашего индекса существенно снизится. В зависимости от итогового результата Сандем предлагает выбрать одно из следующих домашних животных:
• если Fido менее 1, то даже морские рачки будут слишком обременительны;
• если Fido составляет от 1 до 2, попробуйте завести золотых рыбок;
• если Fido составляет от 2 до 3, можно завести кошку;
• если Fido превышает 3, то можно взять собаку.
Джин Хо подставил собственные значения в это уравнение и получил значение индекса готовности к заведению домашнего питомца 0,7, а значит, ему не стоит рисковать даже с кактусом.
Конечно, кто-то может сказать, что слишком большая точность расчетов при решении данного вопроса не требуется, но так или иначе этот пример показывает, что даже очень субъективные и банальные решения можно оценить количественно и смоделировать.
Какие переменные отобрать, а какие отбросить – зависит от цели разработки модели и того, связана ли переменная непосредственно с решением проблемы. Например, если вы рисуете карту Нью-Йорка, то расстояния между точками имеют большое значение и должны быть пропорциональны реальным расстояниям. Однако если вы рисуете схему нью-йоркского метро, то расстояния между станциями на карте совсем не обязательно должны быть пропорциональны расстояниям на местности. Ведь главная цель схемы метро – это показать, как можно добраться от одной станции до другой.
Еще один прекрасный пример важности тщательного выбора переменных модели – это спор по поводу того, кто является автором серии опубликованных в 1861 году писем. Десять писем, подписанных Квинтусом Куртиусом Снодграссом, появились в New Orleans Daily Crescent. В них мистер Снодграсс (ККС) описывал свои военные приключения во времена службы в Национальной гвардии Луизианы. Сразу после публикации письма не привлекли особого внимания. Они впервые попали в поле зрения широкой публики лишь в 1934 году, то есть спустя семьдесят три года после выхода из печати. О них в своей книге Mark Twain, Son of Missouri упомянула Минни Брашер. В частности, она привела текст одного из писем, пересказала содержание трех других и сделала смелый вывод о том, что «письма ККС имеют огромное значение в качестве свидетельства становления Марка Твена как юмориста; именно Марка Твена следует признать их автором, а некоторые различия в стиле можно объяснить его стремлением выработать свой собственный литературный стиль»[29]. Оставшиеся шесть писем ККС опубликовал и проанализировал Эрнст Лейзи в 1946 году[30]. Проведенный им тщательный анализ аналогий позволил утверждать, что письма действительно написаны Твеном, но кое-кто из литературных исследователей до сих пор считает, что у них был другой автор.
В русле исследований вопроса о том, действительно ли Шекспир был автором всех приписываемых ему произведений, Томас Менденхолл в конце двадцатого века опубликовал две статьи, в которых изложил статистический подход к проблеме определения авторства. Топ-менеджер нефтяной компании Клод Бринегар, имевший хорошее университетское образование и увлекавшийся коллекционированием первых изданий книг Марка Твена, изучил историю вопроса и применил метод Менденхолла, впоследствии получивший название стилометрии, или количественного анализа литературного стиля, к письмам ККС.
Этот метод основан на предположении о том, что, хочет он того или нет, каждый автор чаще использует одни слова, чем другие, и сохраняет одинаковый литературный стиль, по крайней мере в долгосрочной перспективе. С позиций количественного анализа это означает, что доля слов определенной длины будет постоянной во всех текстах, написанных данным автором. Если доля слов определенной длины в двух разных текстах существенно отличается, это можно считать подтверждением того, что тексты написаны разными авторами. В качестве переменных для анализа писем ККС выбирались слова различной длины, и их удельный вес сравнивался с аналогичными показателями из работ, определенно принадлежавших перу Твена. Для проверки авторства проводился тест по критерию согласия. Результаты тестирования показали, что расхождения по набору переменных слишком велики, чтобы считать их случайными, – поэтому вряд ли Марк Твен является автором этого произведения (подробности см. на сайте книги)[31].
Далее в этой главе мы еще поговорим об анализе текстов (в противоположность анализу чисел), а пока отметим, что Бринегар в процессе анализа перевел слова в числа.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОК